�������Ϸ��Ⱦ���̸
�����ʱ���������ٵ������Ƿdz����ӵġ�����Ϸ�ÿ�����������Ĵ��ڶ����������������һ���ӡ����Dz�������Ӱ��������������ʱ������Ҫ�������κ�һ��СƬ�εĶ�̬��Ƶ���״̬���������Ǹ��dz����ӵ����⣬���˺ܾö�û���������һ��˼·����������˵�����Ȩ�ҹ���λ����һ�°ɡ�����������ϣ�ÿ���о�������ʦ�������Լ���һ������������Щ�ַ��Ǹ��˶��صģ�����Щ����ҵ�ƶ���һЩ��������������Ϸ��˵����������10����100���������Ǻ����ģ�����Ҫƽ���ǧ�����������Ƶ�����ȣ��Ǿ���ȫ����һ�������ˡ���������������������ı�������
����Ƶ��Ŀ��ƣ������Ǻ������͵���������ʹ�����ֺ���������ҪΪ����������ԣ����ȿ��ǵ����������ó��㹻��Ⱥ�Ƶ��o����������������ȿ��Ƶĵ�һԭ�� ����������˵��ԭ��һ���dz��漶���ȫ��̬Ƶ�죬������Ϸ��͵�Ӱһ��������Ҫ�ó��㹻�ռ䣬����ʱ������Ӧ����ȫƵ�εġ�
Ŀǰ���������ձ���õ�����RMS��Ȳο������£�
���֣�-16dB
��������-16dB
����: -12dB
In-game��Ч: -16dB
UI: -16dB
���������з�ֵ��������-3dB��ÿ��������RMS��Լ������2dB���������ռ䣩
ͨ��������������FMOD�����趨���£�
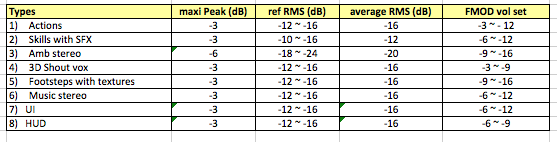
�������ϵ�£���Ӧ�ij��������ǣ�
����Ϊһ����Ϸ�趨һ����������ϵ��“��������”������ζ�ţ���������������ʼ����Ϊ�������������ޣ�ֻ����ijЩʱ�������ٲ����������ڻ����Դ�������ο�����������������ѡ����Ƕ�(���Ǻ�����������Щ���ʦ������Ŀʵ�������Ҳ��ѡ����������UI��Ϊ�������ա�
ͬһ�����͵�������������β��š���������ʲô������ȷ�����ǵ�RMS��Ƚӽ���Ӧ����ֵ��Ҳ����˵����������������������RMS������-16dB���ҡ�
����Ϸ�У���Щ����������ƽ�⣬������Ҫͨ��SoundEvent����SoundCue������������Roll-off�����Ƚ��С���ˣ�����ƽ�������ʱ�������һ����ȷ��“��”����“���ָ�ꡣ
��ɫ�ʡ�Ƶ�췽��IJ�ο���������ʵ����Ŀ�к��ڡ�����80%����Ҫ��Դ��������Ϸ�ſ�ʼ�Բ�ͬ���ܵ������ٽ����Ż�����Ⱦ��������Ҫ�������ľ����Ƶ�졣����ٵ���sound event volume��
���ִ�����Ⱥ�ƽ��ĵ�˼·�������ǰѵ�������������һ������ȶ��������ϣ����ͨ���������ƺ�ƽ�������������ȡ�����“��ͳ”��ƽ���ַ������൱����ĵ����ģ�Ҳ�ǻ�����ҵӰ�Ӻ�����������������۵Ļ������顣����ƽ��ķ�ʽ���Ծ�̬����Ϊ����������һ���̶ȵĶ�̬������ԭ���ϣ���̬����ƽ��Ҳ��������Ϊ��Ҫ�ĺ������ַ�����������Ŀ��ǰ�ڽΡ�����������ֱ�Ӻô����ǣ��κνΣ�������������Event Volume��ϵ���������ȷ�����������������ȥ�жϡ���Ȼ������˼·Ҳ����һ���Ƚϴ�����⣺���ŵ��ż��Ƚϸߣ���Ҫ���ʦ�зdz��õĻ���ѵ������������������
Ӧ��˵����Ҳ��Ŀǰ��������������������������ڽ��������Ӱ��ְҵ������רҵ��ʿת����Ϸ��������˼·�õ��˸���ķ�չ��Ŀǰ������ҲԽ��Խ��Ҫ���ʦ�߱�������˼·���쵶���Ǹ�������˼�����ӡ����ҽ��ֵ�ʱ�������ĵ�һ�������ǣ�
��ÿһ�����ͣ����ࣩ�������������������һ�飬��Щʱ���������ص�������ȡ������˵���ܴ���ͻ������嶯����Ϊһ�顢����������̨��������Ϊһ�顢ս�����ֺʹ�����������Ϊһ�顣��Ҫ��������Щ�����ڸ��������е�ƽ����Ⱥͻ�����ȲΧ��
������Щ���͵�������FMOD�������������趨������Լ�ͨ��һЩ������������ʵ���������Ҷ���������������ʵʱ���������֮��Ĺ�ϵ��������˼���ǣ�ÿ�����桢����ͬһ������IJ�ͬ�汾������������϶������ܴ��Ҷ���ץ�����е����ϵ��һ���dz��̼��������˶���������
�����֮����Ҫ������RMSֵ��FMOD Event Volume����Ϸ��������������������֮����һЩ��ȷ�Ĺ��ɣ�������ɻ�ֱ��Ӱ������һ����ƽ����Ż��ַ���
�ҵ�ʱ�õ��Ľ����ǣ�
���ֻ�������������������Ļ�����Ȳ����Լ10-12dB��
ͬһ�����͵����������ƽ����Ȳ��Լ10dB���ҡ���Щ���������ͬһ�������Ļ�����̬������ֲ��ֺ߳����֣�Ҳ���������10dB�IJ
�����ķ�ֵ��RMS��ԱȽ��ȶ�����ÿ�������ε�¼���ܲ�רҵ����Ͳλ�á����ź�ǰ������Ա�ķ����㶼���ڷdz����������Щ����������Ϊ���ڵIJ�ǡ��ѹ�����������·������dz����ԡ�
���ܺͶ�����ЧRMS��������죨��ͨ֫�嶯���ͼ��ܣ�ƽ����Լ��9dB���ң�����Щ���ܵĸ�Ƶ�͵�Ƶ���Թ����ˡ�
����������Ƶ�����ȣ���Щ��Ƶ���ࣨ��Ҫ������Ϸ���鱾���������жϣ���������Ƶ����첻���Ǻ��ں�����Ҫ��ƽ���IJ��졣
��Ϊ���ҵ�ʱ��̣ܶ����Ե�һ�����������ȿ��������������Ŀ����������
ƽ�����������������Ƶ�죬��������������ͬһ�����������ġ���ȡ�����ܴﵽͳһ�ı���
�Ż����ʣ���������������������ɫ���Եù��ڴ��ӡ�
˥������������16kHz���Ϻ�60Hzһ��Ƶ�Σ���ͬ��������˥������Ƶ�����в��죩
���쵶�������Ƚϸ��ӣ��ڰ汾ѹ���£����ײ���֮����˳��Ȼ�Dz����ǵġ�����ʵ�İ취�dz���������л��ƺ������ֳ����������������ɣ��Ӷ��õ�һ���ȽϿ����ְ�ȫ�Ľ�������������ƶ��Ļ����������÷������£�

����ݱ�������г��˵�ǰ������FMOD�Ļ���������Ҳ�г���Ŀ���������Դ���Ϊ�Աȡ�����ݶԱȣ����۶������ڵĹ������Ǻ��������汾���趨�����Ǿ��зdz���Ҫ��ָ������ġ�
ע��
��ݱ�������������������Ǿ���ֵ������ͨ�����������ȡ������õ�ƽ��ֵ��
��ЩĿ��������������Ϸ�������İ汾����һ���ij��룬����������£����뷶ΧС������3dB��
������Щ��ֵ�������ҵ�һ����������RMS��Ƶ���Ż�ƽ���õ��ģ��������ܵ�һ������ƽ��ľ����ַ�����������������û�й��ɵ�����µõ��ġ�������Щ��ֵ�ı仯���Ƿdz������绷��������ͨ�����趨���ڷdz�����졣��Ҫԭ�������쵶���õ�FMOD�汾�3D����˥���������������⣺��Event Vol= -6dB��ʱ��������Ϸ��ʵ�ʱ��ֳ�������˥����Լ��-10dB�����˥���ʺ�SoundMood������Ҳ���൱��Ĺ�ϵ��
���һ�е�FMOD Vol.Set����ǿ��Կ�����ͬ��ε�������FMOD�X��û��̫��IJ��졣ʵ���ϣ��������Ǻܲ������ġ����ݹ߳�������������������̬���첻��FMOD�����趨�Ķ�̬Ӧ�ñȽϴ�Ŷԡ�������Ҫԭ���ǣ��ܶ�EVENT������multi-layers�ṹ�����Ҵ������õ��û��Զ���������ʵʱ���㡣��һ��ԭ��Ҳ�������ᵽ��3D����˥�����йء�
��������������ϵ���û�в��õ�����Ƚ��ձ������������͵���˵ġ����װ취�������������Ƕ����쵶�����Ŀ�������˵�����������������ʵ��һЩ���Ӳ�ͬ�е�ɫ�ʱ�ע���Ҳ���Կ�����������趨����˵����������Ҫ������Ⱥ������ɫ�ʡ���̬��Ƶ������Ϸ���γɲ���ϵIJ��졣
�ڽ��е�һ�������Ż�֮ǰ���������������飺
���߳���������ȣ�С��ģ����һЩ��������������������������Ҫ�ǣ�һ����ͼ�����ֺͻ�������
�滻FMOD�����Щ���������Ԥ�ƵĹ߳���������Щ��������������Ϸ�������������������ʵ����һ��������һЩ��Ҫ���������缼�ܣ�ԭ�����ڣ�����Ҫ����һЩ��������������Ϸ�����Щ�Ĺ����������Աȣ�����Щ�µ��趨����Ϸ��������������ķ�Ӧ������ַ���ʵ����Ϸ�����Ż���ʱ��Ҳ����Ч��
���еĵ�һ�δ�������������������������͵���������������������бȽ������һ���������ӹ���������������Soundforge�������������
����������Ҫ����unltra-funk reverb��EQ������ɫ��ƽ�⣬�ó���Ƶ����Ϊ���ɲ�����Ҫ���й����������й�������Ҫ������800-2000Hz��Ƶ��Χ�ڡ������Ķ��������������Ե���Զ������������й���������˵�����б��������ữ��������������������ƽ��RMS�ﵽ�ƻ�ָ�꣬��ʱ���߳����䣩������-14dB����Ϳ��Ѻܴ�Ŀռ��ó������������ˡ�
ս�����ֲ���Ƚϴ��������������������EQ������˥���������ǵ���Ⱥ�Ƶ�����������������ô��Ȼ��������������һЩ��ʱ���졢��EQ�г���Ƶ��˥���е�Ƶ������50Hz����Ҳ˥��һЩ����Ϳ��������ǰ�Ƶ��ռ��ó��������ܺͶ�����ƽ��RMS�����ڼƻ�ǿ���ϡ�12kHz����Ҳ����˥����������������12kHz������˥���ñȽ��٣���������������ϸ�����кͿ������͵������ֳ����ˡ���
����ͳһ˥��16kHz���϶ࣩ��12kHz�����٣������ʹ̶��У�����˥��250��500Hz�����������ɼ��������趨�IJ��죬Ϊÿ�����ɵ�EQ�ٶ�һ����Ⱦ�ԵĴ�����ǿ�����ɼ��ɫ�ʲ��졣
�����������������������ص㣨�������е�ɽ�Ȱ���Ϊһ�ࣩ���ֱ�����������ͳһRMS��Ƶ�졣����û���ǿ���������Ⱥ����������ȽϿ�ǰ�����û������û�����Ⱦ��������������һЩ�����EQ��Ⱦ������Щ������16kHzҲ��˥���dz��࣬��Ҫ��һЩ֪�ˡ���ͷ磬������Щ������4kHzҲ��˥�����ܶ࣬һ�����������Щ������������������ƽ���ںϡ��������Ե�̫ͻأ����һ����Ҳ��Ϊ�˻����͵����С�
�����Ƚϼ��֣��ô�ͳ��EQ��ѹ��ɶ�����ܽ��¼���ͷ��������ġ����ô�Ⱦɫ�IJ������ǿ��Ⱦ����������������������һЩͬ���������ص㣬��˾Ϳ���ǿ�������ʲ����С����������Dz����ѵģ�Ҳ�DZȽ�Σ�յġ�������12kHz��Ƶ��ʵ�е��Ƚ϶࣬��Ҫ��Ϊ���������Եø���ů������ģ��¼���ĸо���ͬʱҲ���Թ��˵��й���Ա�������ձ��ȱ�ݣ������������ֵ�˻˻��������ʵ�������ͻ�Ͳѡ�����λҲ�кܴ�Ĺ�ϵ����
BGM����Ϸ�ڷ�ս�����ֵ����֣�������������������ã�
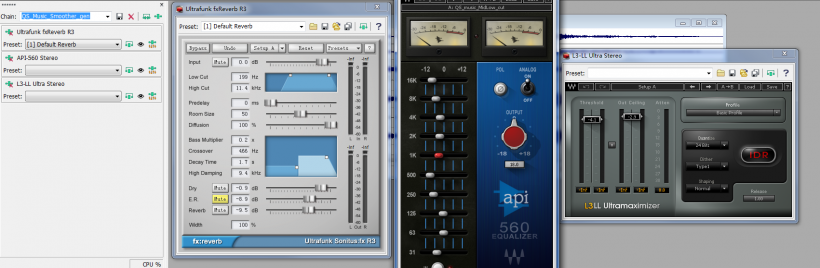
��Щ�������;ֲ��������ص㣺
���ȣ���Щ������������Ե�Ⱦɫ��һ��������Ϊ�ҵĸ���ϲ�ã��������������ԵñȽ���ů����һ�����ձ��˥��12kHz���ϣ�����������Ϸ������ָ�Ƶ�ϵ����Ե��ӣ����һ�Ƚ���������ģ�����ʵIJ�������ڸ�Ƶ��ɫ�������÷dz���ɫ����ů���������Ƶģ������õ���������Ϸ���Ƶ����ʧ����Ϸ��ʵʱ�����ܹ������һ���Щ�����еĸ�Ƶ�ġ�ʵ���ϣ�ÿ����Ŀ���ܶ���Ҫ�趨һ����Ⱦ�Բ���ķ��������������Ϸȷ��ijЩͳһ����ȷ��ɫ�ʡ����ɫ�ʻ��Ϊ������Ϸ�����ϵĻ�ɫ��
����û�ж�����������Ҫ����ȫƵ�εģ����Ҵ�������500-1000Hz���ֶ��õ��˲�ͬ�̶ȵ�˥����50��60Hz����Ҳ����˥����ԭ���ǣ���������������Ƶ�β��ַdz�������ɳ�ͻ���ߵ��ӣ����ܴ��С���ը����ײ���Ľ���Ƶ�μ�����150-600֮�䣩�����������Ŀռ���Խ��ԽС��ֻ�е��������ÿ��������ÿһ�ֹ������͵��������ó��ض��Ŀռ䣬һ��������������������������ȷ����һ����Ҳ�����������ó��㹻��Ŀռ䡣
Ultrafunk Reverb�������Ƚ��ر�����Ҫ����һ���dz��ɾ���û�����Կռ�к�Ⱦɫ�Ļ��졣�������ѡ����Sonnox Reverb������...����������ѡ���������ͱ�ͣ���IJ����Ultrafunk���Ҳ������ϲ���IJ��Ʒ��֮һ������Modulator��DelayҲ�Ƿdz����ģ����Թ㷺���������Ρ���������ϵ���ָɾ�������ʱ������������Ȳ���Ϊ�˻��ij�ֿռ�����������Ϊ�������ֺ������������õ��ںϡ������ַ���Ӱ�Ӻ����ֵ��ջ���dz��ձ顣ͨ��ԭ����Ƭ�����ֵĻ������Ա���Ϸ������ֻ���Ҫ�ɺܶ࣬Ҳ�����ԭ��
ÿ�����������꣬�Ҷ�Ҫ����������������RMS״�������һ�Ҫ�ö�����һ�¡�ͬʱ��һЩ�ֲ����ġ�ԭ�����ڣ���ʹ����������RMS��ͬ�������������������ھ�����Ҳ���ܴ��ںܴ�IJ��죬����������Ҫ��������ģ�����ijЩ������ȷ����Ϊ��ij�־�����ʹ�õġ����⣬��ͬ����������������������Ƶ�������ϴ��ڲ���Ԥ�ƵIJ��죬Ҳ��Ҫ���ⲽ���Ͻ������
3D��Ȼ������������һ���������������ã�
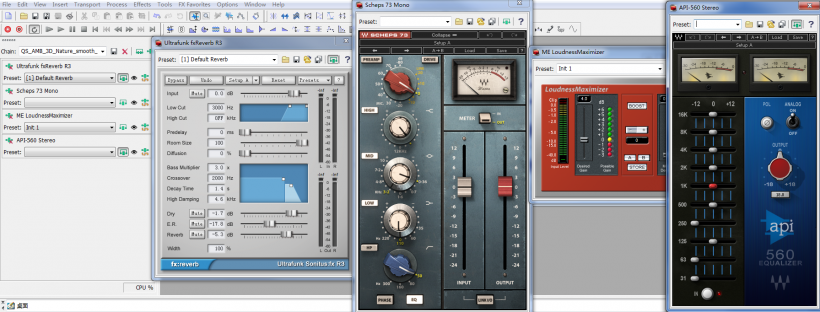
���ϲ��貢��Ҫ������ξ���ÿ������100%�ﵽ����Ч����Ҳ��Ҫ����һ��100%������������⡣��һ�����Ŀ��ֻ��һ����ȷ��90-95%�������ܹ��ﵽ�ƻ�����Ⱥ�Ƶ��ƽ��Ϳ��ԡ�����ǣ�����Ϸ�����ǿ���������û���ر���������Ҳ�ǶԵģ���Ϊֻ���������������ȷ֪����ν����Ϸ��������������֮��ĸ��ܹ�ϵ�����˵��һ��Ҫ����һ����Ĺ�������ô��һ�ε������Ե������ǵ�Ĺ����ˣ�ֻ����“��”�ܶࡣ���ҵIJ����ǣ��Ƚ����ĵ㣬�����ϸ������ν“��”�ĵ���������Ϸ���顢�����Ǿ�����ء����͵������Ľڵ㡣
��������ܲ��裺
1. ��Soundforge������������Ҫ�IJ������
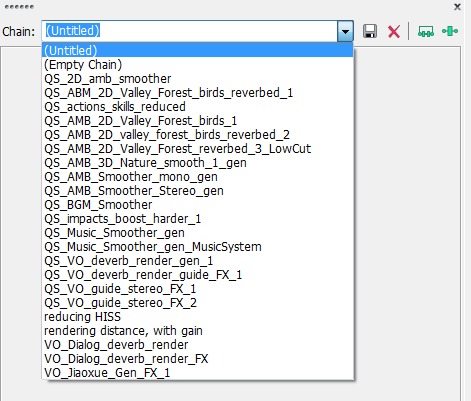
2. ����������֮������Щ����ʹ�ù��IJ����(��.bj���ļ�)
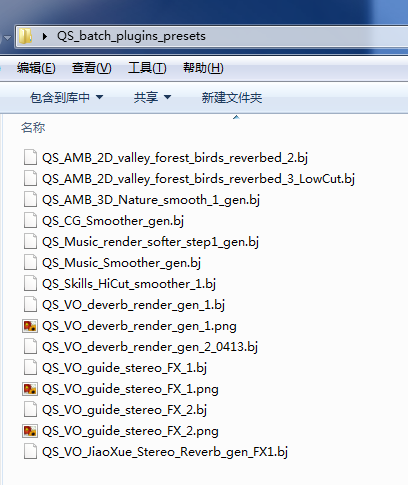
�����һЩ���õ������������磺
*** ��Щ������Ԥ��Ϳ��Ա������쵶�Ĺ����ĵ��ں��Ŷ�������ԱЭ��������Ҳ������Ϊ��Ҫ���ݴ浵������ں������ݵ����Ӻʹ�����������Ҫ�ġ�
*** ϰ���ڵ�������ﱣ����Ŀ��Ҫ��Ԥ��Ҳ�Ǹ��dz��õ�ϰ�ߡ�
�ڴ�ͬʱ������sound event����������Ҳ��0��-3dB��-6dB��-9dB����3dBΪ���ݵ�λ����������ͼ���У������������ԭ�����Լ�������ѧ����Ԥ�ڵĽ��һ�����ڶ���İ汾�������������ȺͶ�̬�仯��þ����ˮһ��ƽ����ζ����Щ�ط���������ʧ����һ����ԭ�����ڣ�֮ǰ��Event����������ú�ϸ�£��Ѿ����ֳ������µľ����ˣ��������ڵ�����ƽ���Ե�̫�й��ɡ�“����”�Ƿdz���Ҫ�ģ���Ϊ��ͬ��ε�������������й��ɣ�������Ϸ��ҵ�����ͻ������ȷ��ͳһ����һ�㣬������ϸ�۲���Щ���磬��ʹ����10������ͬ��ε�����������Ƶ�������Ȼ��һ������һ����Ҫ���������λ���������˵����һ�����������ȫ��ͬ�ģ������µĽ���״������ϵ������Щ��ͬ���������IJ�ι��������˳������������ϣ���ġ������ǵڶ���Ҫ���ľ����������ϸ�ڣ�ȷ��ijЩ��������̫�����̫С����������Ϸ������ҪһЩ�����Ƶ�Ρ������ַ�Ҳ�ǣ���С����ij�ȡ���ԣ�ͬʱ�ҵ���������ֵ�����������������Ϸ����һ��Ҳ�ǽ�һ����������ƽ��Ͳ�Ρ�����������һ���ô��ǣ���ͬ��Ҳ������������������߿�����������Ⱦ�㡣ֱ����һ����ƽ����̽������ҲŻῪʼ����ijЩ���������ر�������ʵ�ϣ�����ǰ���ᵽ�ģ����վ���������FMOD�ﶼû�л������õ�-9dB������-6dB�ļ��ʶ��ܵͣ�ԭ���������FMOD�汾�Ͷ���������˥����������һЩ������ȫ��֪�����㷨�������ܹ�ȷ�ϵ�ֻ�ǣ�6dB��ʼ������˥���ٶȳ��ֱ��������飬���Ǽ��䲻�����ģ���Ҳ�Ƕ�ʱ���ں��ѻ�ʱ��ȥ������ġ�
������ÿһ�����͵�����������֮ǰ���Ҷ�ÿ�����͵��������������㹻�������������ȡ���ԣ��Դ��ҵ����������Ⱦ������������ȡ������ܹ�ȷ���������κ�һ���������ݶ��ܹ���������Щ��������ⲽ������������Ҫ����ģ�Ҳ�Ƿdz����ԵĹ�������������Ҫ������֤���鹤����RMS��Ȳ��ԡ���������жϽ�ϡ�������Ҫǿ�����ǣ��������������ʹ����һ�������������˵��Ҳ����Ҫÿ�칤��ǰ��һЩ���������ġ���ν������������ÿ��һ��ȥ��һ���Լ�����Ϥ�����ֻ���soundtrack������Ҫ��һ��ǰһ�촦����Ķ������Ӷ�ȷ���Լ��������ж���ϵÿ�춼��һ���ġ�������Щ���ֵ���Ⱥ�Ƶ�촦��������������������Լ���������������Ϊ��Щ���������漰�������ɫ�������⡣�ȶ��������жϰ�����Ƶ�졢������������ȡ�ɫ�ʣ���Щ�ж϶�������Ϊ�Լ�������������״�����ܵ�Ӱ�졣�ȶ��������жϣ���ȷ����Ҫ����ѵ���ġ��ٸ������ӣ������һ�����������زĿ⣬�������ж���������������������ȡ�����������ȵȵȻ���Ҫ�ض��Ƿdz�ͳһ�ģ�����ɫ��Ҳ����ȷͳһ�ġ����ԣ��õļ���ϰ�ߡ��ȶ���ȷ�Ŀ�ζ���㹻�õ�Ӳ���������Բ������������ã�����ֱ��Ӱ�쵽����жϺͽ������Ҳ��Ϊʲô��ҵ�ﶼ�Ƚ��Ƴ�����¼������ȥ¼�زĵ���������������Ϊ�˸��õĴ�����������أ������ĺ����������Ż���������һ�ַdz���Ч��ѵ����
�ڴ���������Ⱥ;����ʱ����ʵ������һ���dz����ֵ����⣬Ҳ��һ���dz����͵����⡣����ԭ�ƻ������ò�ͬ���ϳ��ֵĶ׳��ֳ���ͬ�ľ����Ҫ���������в�ͬ��Ԥ��Ⱦ��������������B������Ƚ�ƫ�������볡����������Ҫ��һЩ����Ԥ��Ⱦ�����Dz������ȫƵ�ε�������������������״̬��ǿ����������дʽ��ȫƵ�δ���������������Ե����ֳ���һЩ����ƫ�����ܶ�Ƶ�λᱻ�������������2�ס��Դ˾Ϳ��Գ��ֳ���Ӱ���IJ���ص㣬��Ϸ���ԣ�����Ҳ��������Ȼ�������е��ļ������ͽ�ɫ�����Ĺ��ʽ���������������ǿ��Կ�����ȡ�����ַ��ʽ����Ҫ����������������������Ϊ�����ַdz��Ӵ��ֻ�����գ�ת����ȡ�ֱ���ͳһ��Ⱦ�취������ֻ���չ����ԡ��������Ҳ�㷺�����ڶ����ͼ��ܷ��档����л���Ŀ����������ݣ���ᷢ�ֵ�������������������ʵ�dz�������Щ��Ŀ���������������������¼�����εı�š���Ϊ�������漰�������ֵ����⣬���Ի������һЩ����˿��Կ�������Ϸ��ƽ�����ȿ��ƣ�������һ����Ҫ��ϸ�滮��ϵͳ���̣����ļ��ṹ���ļ����ơ�������ʵʩ�����ȵ�ÿ�����ڶ�Ҫ�ۺϿ��ǵġ�
����һ������Soundforge��ʹ�õ���Ҫ���:
Waves All(��Ҫ��REQ 4, API560 EQ, API2500 compressor, Schopes 730��NR)
Ultrafunk
Steinberg Masterting Edition
����������ȵ���Ҫ���ƻ��ڣ�
���֣�ԭ���������ڶ�����������ģ�����Ϸ����Դ
������¼������Ͳ�ͺ����λ��ǰ���ͺ������á�������ѧ���ƣ�������ƽ�⡢������ɫ��
��Ч����ʼ�زġ���Ϸ���м���زģ�����ƽ��ǰ���������زģ�����ƽ���������زģ�
��Ϸ��CG��ԭ���������ڶ�����������ģ�����Ϸ����Դ
����Ƭ�������������߾��Ȱ汾�����緢���汾���;��ȸ�ʽ��CPЭ����
�
������ȵ����⣬�Ҷ���ǰ����Skywalker��ʱ��Ҳ��̹�����������˺����ʦ�����������ᵽ����Щ���̿����⣬��ʵ���Ƕ���ͬһ��IP�IJ�ͬý��汾�����н�Ȼ��ͬ�Ĵ����Ϳ��ơ��ȷ�˵Star Wars�ľ糡����������Ҫ֧��THX������ͥ������Ҫ��THX��DTS��Dolby AC-3��Doldby Stereo��������Ƭ���ݣ�����������Щ��ʽ�⣬���и�������ý��汾������Vimeo��Youtube�� Quicktime��������Ҫ����iPhone��iTunes֮��ġ����ڲ�ͬ�IJ���ý�飬����ͨ����Ҫ����У��ȺͶ�̬�ģ�������ʱ�����ջ��Ҫ��ͬ�汾�������ǻ�������֮���ٵ�������ͬ�汾����Ŀ����Ϊ���ڲ�ͬý���϶��ܱ��ֳ���ѵ����С��������Ŀǰ��EA��UBI֮�ഫͳ��ͷ��ϵ���Ѿ��ܽӽ�Ӱ��������������ܶ�ʱ������Ƭ��CG����������ר�ŵ��Ŷ�����ɡ����ȷ���ಿ�ŵ�Э������ȺͶ�̬Ƶ���ϱ���һ�£�ȷʵ��һ���dz����ӵ����顣���У�������Ա��רҵѵ���������̡��Լ����������ռ�����ʶ���⣬���ߵ�ͳһ��Ӳ��������ʩ��ͳһҲ�Ƿdz���Ҫ�Ļ��ڡ�
���⣬����Ŀ��һ��ʼ���趨һ���漰���л����������͵ļ����ĵ������������������ȵ����ŷ�ʽ�����뷽ʽ�����Ϸ�ʽ��Ҫ�������ڡ���Ӧ�ģ�ÿ�����͵�����Ƶ���붯ָ̬�ꡢ¼�����̡��������̡����������̡���������ȵȣ���Ҫ����ȷ�����ֺ����ݼ�¼���档���Ǻ���Ŀ�顢CP֮�䲻����������ʶ��̬�������ϵĹ�ͨ������Ļ���Ҫ�㹻��ļ�����ͨ����������Ŀǰ�ڽΡ�
�������ݹ�̽�ֺͲο������д�©���븫������ʤ�м���
ת��MIDIFAN
| ����ӡ��ҳ����������ҳ�� |