MusicGen 是如何通过参考旋律生成音乐的?
2023年6月13日,Meta(前身为 Facebook)发布了生成音乐模型 MusicGen,在音乐和人工智能社区引起了轰动。
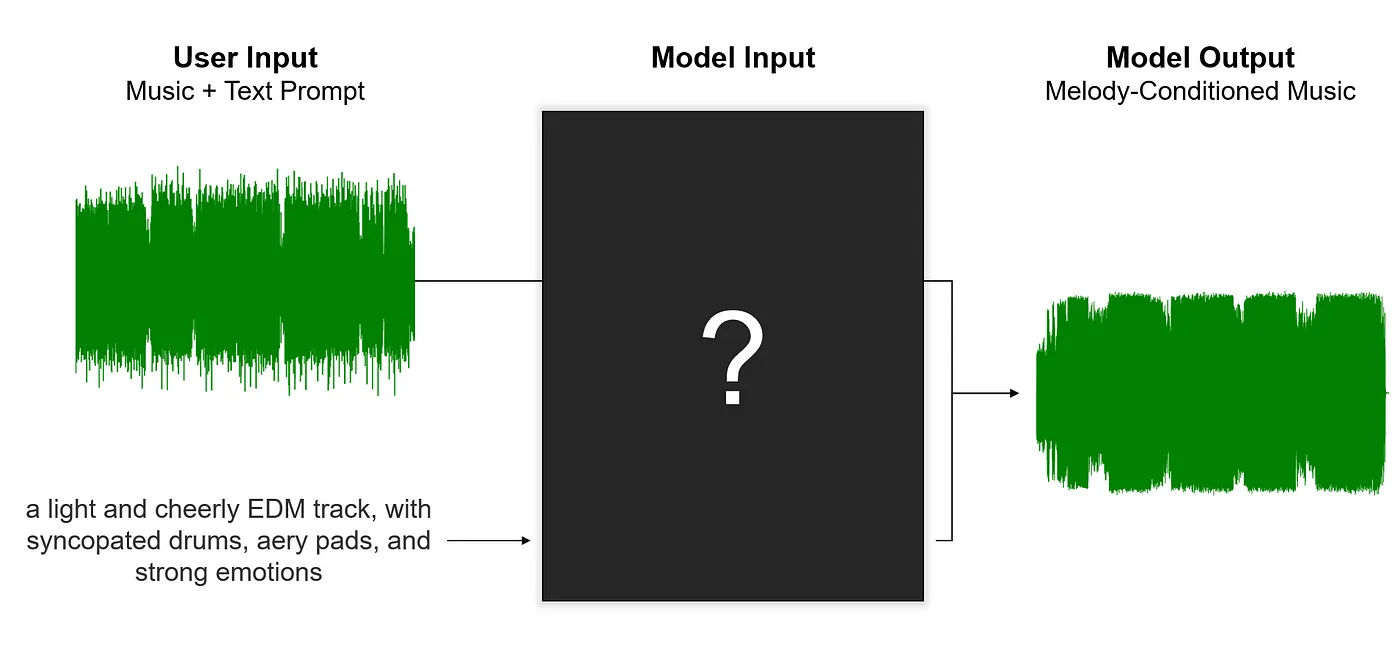
图1
Meta发布MusicGen
2023年6月13日,Meta(前身为 Facebook)发布了生成音乐模型 MusicGen,在音乐和人工智能社区引起了轰动。 该模型不仅在某些方面超越了今年早些时候谷歌推出的MusicLM,而且利用的是授权音乐数据进行训练,并且开源给非商业用途。现在不仅可以阅读研究论文[https://arxiv.org/abs/2306.05284]或试听[https://ai.honu.io/papers/musicgen/],还可以直接从GitHub [https://github.com/facebookresearch/audiocraft] 或在HuggingFace [https://huggingface.co/spaces/facebook/MusicGen]上的在线应用程序中体验该模型。
除了根据文本描述生成音频之外,MusicGen还可以根据给定的参考旋律生成音乐,这一功能称为旋律条件限制生成。 这篇文章将演示Meta如何在他们的模型中实现这一有用且令人着迷的功能。在深入研究之前,让我们首先了解旋律条件限制生成的原理。
音乐效果如何?
虽然在测试中MusicGen并没有严格遵循文本提示的要求,并且创作的音乐与要求的略有不同,但生成的作品仍然准确地反映了所要求的音乐流派。更重要的是,每首作品都展示了自己对主旋律的不同诠释。虽然结果并不完美,但是该模型的功能令人印象深刻。 自发布以来,MusicGen一直是HuggingFace上最受欢迎的模型之一。
如何训练文本到音乐模型

图 2:训练MusicLM或MusicGen等模型时运用的三个文本和音乐例子。
几乎当前所有的音频式音乐生成模型在训练过程中都遵循相同的逻辑,依靠一个附有相应文本描述的大型音乐数据库。 该模型学习文本和声音之间的关系,并从中得到将给定的文本提示转换为音乐片段的能力。 在训练过程中,模型通过将其生成的内容与数据集的真实音乐曲目进行比较来优化迭代,这使得深度学习模型能够识别其当前生成音乐的优劣并不断提升。
这种方法的局限在于一旦模型针对文本到音乐生成这样的特定任务进行训练,它就只能执行该任务。 虽然可以试图让MusicGen执行如音乐续写这样未经过明确训练的任务,但不能每个请求都能完成。 MusicGen不能轻易地把一条旋律变为不同的流派。 这就像将土豆扔进烤面包机并期待炸薯条出来一样。 为了实现各种需求,我们必须训练一个单独的模型来实现此功能。
训练配方的小改进
让MusicGen能够根据文本提示生成旋律变奏存在一些挑战。主要障碍之一是识别歌曲的“旋律”并以计算机接受的方式表示。这个问题会在之后深入探讨。目前,为了理解新的训练过程,我们先假设对“旋律”的概念达成共识。在这种情况下,调整后的训练方法可以概述如下:

图 3:三个文本-音乐-旋律配对以用于MusicGen旋律条件限制生成。
对于数据库中的每个曲目,第一步是提取其旋律。随后向模型输入曲目的文本描述及其相应的旋律,促使模型重新创建原始曲目。这种方法与最初模型的训练目标不同。MusicLM一类的模型唯一的任务是根据文本重新创建音频。
为了理解这样的训练方式,让我们想想人工智能模型在这个训练过程中学到了什么。本质上,模型学习的是如何根据文本描述将旋律变成一首完整的音乐。这意味着训练结束后,我们可以为模型提供旋律,并要求它以任何流派、情绪或乐器创作一首音乐。对于模型来说,这与它在训练过程中已成功完成无数次的“半盲”生成任务相同。了解MusicGen旋律条件限制音频音乐生成技术后,我们仍然需要应对精确定义“旋律”的挑战。
什么是“旋律”?
事实上,除非所有乐器同度演奏,否则没有客观的方法来确定和提取复调音乐作品的“旋律”。虽然通常会有一种突出的乐器,例如主唱、吉他或小提琴,但这并不一定意味着其他乐器不是“旋律”的一部分。以皇后乐队的《波西米亚狂想曲》为例,当你想到这首歌时,你可能首先想起弗雷迪·摩克瑞的主唱旋律。 然而,前奏中的钢琴、中间部分的合唱组以及“So you think you can rock me [...]”之前的电吉他也可以算作旋律之一。
提取歌曲“旋律”的一种方法是将最突出最响亮的旋律视为最主要的旋律。 色谱图(chromagram)是一种广泛使用的表示形式,可以直观地显示整个曲目中最主要的音符。 下面是两张色谱图,一个是完整录音,一个去除了鼓和贝斯。 在竖轴上,与旋律最相关的音符(B、F#、G)以蓝色突出显示。
图4
两个色谱图都准确地描绘了主要旋律音符,而去除了鼓和贝斯的版本提供了更清晰的可视化效果。 Meta的研究也揭示了相同的观察结果,这促使他们利用音源分离工具(DEMUCS)从曲目中删除任何干扰的节奏性元素。 这个过程能提取到具有足够代表性的“旋律”,然后可以将其输入到模型中。
至此,我们现在可以将这些流程连接起来,以了解请求MusicGen执行旋律条件限制生成时的底层步骤。 以下是工作步骤的图示:

图5:MusicGen如何产生旋律条件限制的音乐输出。
局限

图6
虽然MusicGen在旋律限制方面做出了有希望的进展,但是该技术仍在开发完善当中。即使移除了鼓和贝斯,色谱图也无法完美地呈现曲目的旋律。其中一个限制是色谱图将所有音符分为12个西方音级,这意味着得到的是两个音级之间的绝对变化,但并没有获取旋律向上或向下的方向。
举例来说,从C4移动到G4(纯五度)之间的旋律音程与从C4移动到 G3(纯四度)之间的旋律音程有很大不同。然而在色谱图中,两个音程看起来是相同的。八度跳跃时问题会变得更严重,因为色谱图会表明旋律保持在同一音符上。 想象一下色谱图如何将席琳·迪翁在“My Heart Will Go On”中“Where-ever you are”这句中的八度音阶跳跃识别为不变的音高。 这样的错误看看下面 A-ha 的“Take on Me”中合唱的色谱图即可。
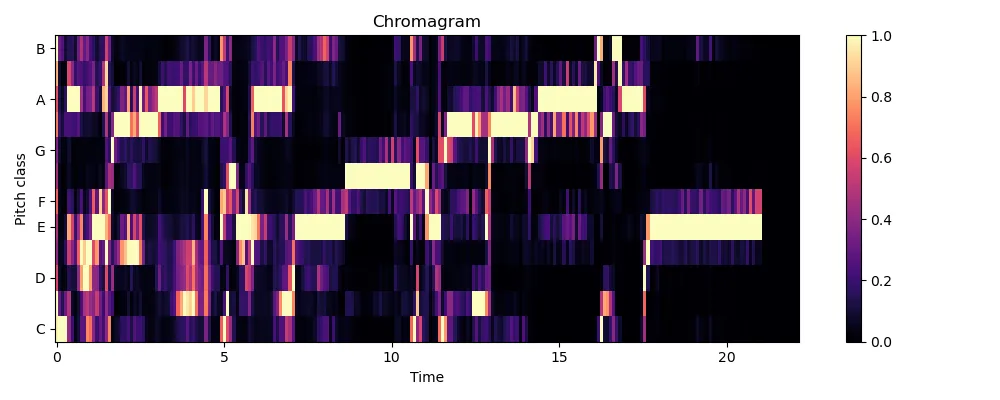
图 7:“Take on Me”移除了贝斯和鼓的副歌色谱图。
另一个挑战是色谱图的固有误差。 色谱图在捕捉某些歌曲的旋律方面表现良好,但在其他歌曲中却完全不行。 这种误差是系统性的而不是随机的。 与旋律复杂分布在多种乐器上并具有较大音程跳跃的歌曲相比,主旋律明确、音程跳跃少、齐奏为主的歌曲可以通过色谱更好地表示。
此外,生成式人工智能模型本身的局限性也值得注意。 输出音频质量表现出与真正音乐的明显差异,并且在六秒钟内的生成内容中保持风格一致仍然有难度。 此外,MusicGen未能忠实地实现文本提示中的更复杂的描述。 旋律条件限制生成需要进一步的技术进步,以达到不仅可以用于娱乐和灵感寻找,还可以直接生成达到最终令人满意的水平。
未来展望

图8
从作者的角度来看,关于旋律条件限制音乐生成的主要问题之一是提取和表示“旋律”的方式。虽然色谱图是一种成熟且简单的信号处理方法,但有许多最新的研究开始利用深度学习来实现此目的。看到像Meta这样的公司从这些研究中汲取灵感将是令人兴奋的,其中许多研究都在 Reddy 等人的 72 页综述[https://arxiv.org/pdf/2202.01078.pdf](2022)中进行了介绍。
关于模型本身的质量问题,几个提升方向包括扩大模型规模、增加训练数据、针对特定任务开发更有效的算法等可以增强音频质量和文本的理解能力。2023年1月MusicLM的发布类似于“GPT-2时刻”。 我们开始见证这些模型的潜力,但各个方面仍需要重大改进。 如果这个类比成立,类似于GPT-3的音乐生成模型发布将比我们预期的更早。
对音乐人有何影响?
正如生成式音乐人工智能的常见情况一样,人们担心它会对音乐创作者的工作和生计产生潜在的负面影响。 在未来,通过编曲来谋生将变得越来越具有挑战性。 这在广告歌曲制作等场景中尤其明显,公司可以毫不费力地以最低的成本为新的广告活动或个性化广告生成特征广告歌曲旋律的多种变体。 毫无疑问,这对依赖此类活动作为重要收入来源的音乐家构成了威胁。 因此,我们呼吁音乐创作者重视提升客观的音乐品质,而不是主观人脉,并探索其他收入来源,为未来做好准备。
从积极的一面来看,旋律条件限制音乐生成为增强人类创造力提供了令人难以置信的工具。 如果有人创作出令人难忘的旋律,他们可以快速生成示例来听听在各种流派中的效果。 这个过程可以帮助确定理想的流派和风格,使音乐栩栩如生。此外,它还提供了一个机会来重新审视过去音乐作品,探索它们在不同流派风格中改编的潜力。 最后,这项技术降低了没有经过正规音乐培训但具有创造能力的个人参与创作的门槛。 现在,任何人都可以创作一首旋律,对着智能手机麦克风哼唱,并与朋友、家人分享他们的精彩编曲,甚至在网络上拥有粉丝。
人工智能音乐生成对我们社会的影响仍然存在争议。 然而,旋律条件限制音乐生成这项技术的实际应用增强了专业和有抱负的创作者的工作方向。 它提供的探索路径可以为社会增加价值。我们期待在不久的将来见证这一领域的不断进步。
录音棚设备解决方案 售前咨询:13366394396
| 【打印此页】【返回首页】 |